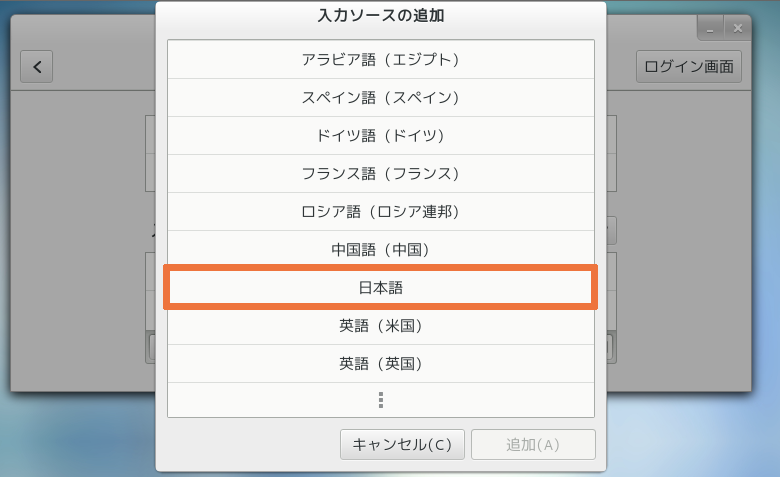
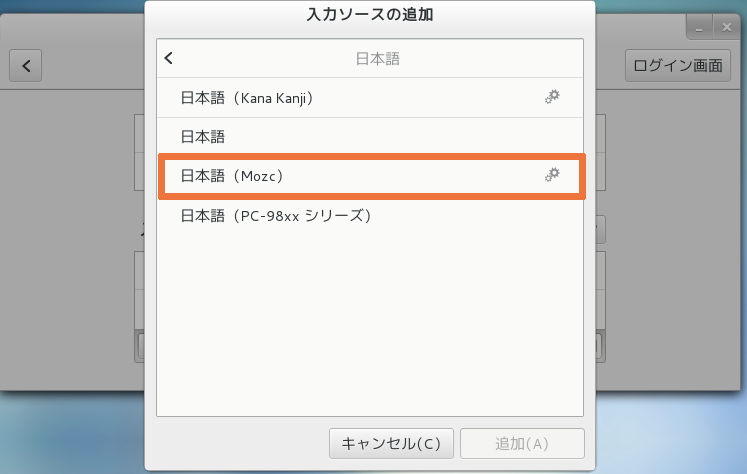
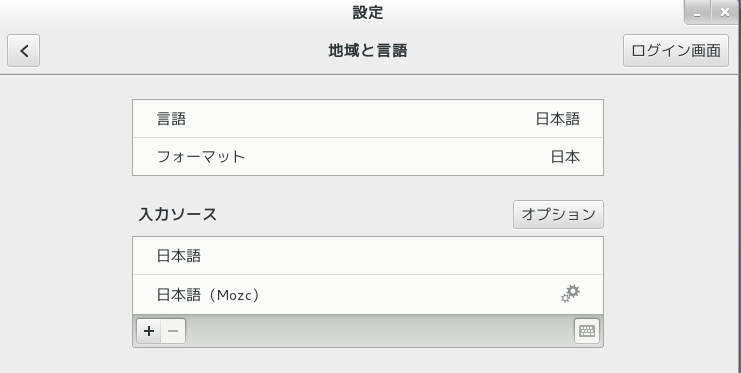
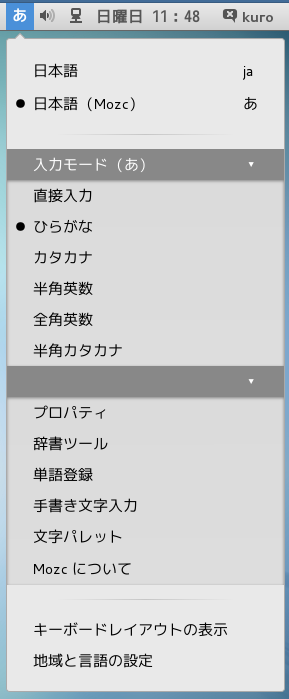
Mojibake (文字化け) (
IPA: [mod͡ʑibake]; lit. "character transformation"), from the
Japanese 文字 (moji) "character" + 化け (bake, pronounced "bah-keh") "transform", is the garbled text that is the result of text being decoded using an unintended
character encoding.
[1] The result is a systematic replacement of symbols with completely unrelated ones, often from a different
writing system. This display may include the generic
replacement character � in places where the binary representation is considered invalid. A replacement can also involve multiple consecutive symbols, as viewed in one encoding, when the same binary code constitutes one symbol in the other encoding. This is either because of differing constant length encoding (as in Asian 16-bit encodings vs European 8-bit encodings), or the use of variable length encodings (notably
UTF-8 and
UTF-16).
Failed rendering of glyphs due to either missing fonts or missing glyphs in a font is a different issue that is not to be confused with mojibake. Symptoms of this failed rendering include blocks with the
codepoint displayed in
hexadecimal or using the generic replacement character �. Importantly, these replacements are
valid and are the result of correct error handling by the software.
To correctly reproduce the original text that was encoded, the correspondence between the encoded data and the notion of its encoding must be preserved. As mojibake is the instance of incompliance between these, it can be achieved by manipulating the data itself, or just relabeling it.
Mojibake is often seen with text data that have been tagged with a wrong encoding; it may not even be tagged at all, but moved between computers with different default encodings. A major source of trouble are
communication protocols that rely on settings on each computer rather than sending or storing
metadata together with the data.
For some
writing systems, an example being
Japanese, several encodings have historically been employed, causing users to see mojibake relatively often. As a Japanese example, the word
mojibake "文字化け" stored as
EUC-JP might be incorrectly displayed as "ハクサ�ス、ア", "ハクサ嵂ス、ア" (
MS-932), or "ハクサ郾ス、ア" (
Shift_JIS-2004) if interpreted as being in a form of
Shift JIS. The same text stored as
UTF-8 is displayed as "譁�蟄怜喧縺�" if interpreted as Shift JIS. This is further exacerbated if other locales are involved: the same UTF-8 text appears as "æ–‡å—化ã‘" in software that assumes text to be in the
Windows-1252 or
ISO-8859-1 encodings, usually labelled Western, or (for example) as "鏂囧瓧鍖栥亼" if interpreted as being in a
GBK (Mainland China) locale.
Underspecification[edit]
If the encoding is not specified, it is up to the software to decide it by other means. Depending on type of software, the typical solution is either configuration or
charset detection heuristics. Both are prone to mispredict in not-so-uncommon scenarios.
The encoding of
text files is usually governed by the
OS-level setting, which depends on brand of operating system and possibly the user's language. Therefore, the assumed encoding is systematically wrong for files that come from a computer with a different setting, for example when transferring files between Windows and Linux. One solution is to use a
byte order mark, but for
source code and other machine readable text, many parsers don't tolerate this. Another is storing the encoding as metadata in the filesystem. Filesystems that support
extended file attributes can store this as
user.charset.
[2] This also requires support in software that wants to take advantage of it, but does not disturb other software.
While a few encodings are easy to detect, in particular UTF-8, there are many that are hard to distinguish (see
charset detection). A
web browser may not be able to distinguish a page coded in
EUC-JP and another in
Shift-JIS if the coding scheme is not assigned explicitly using
HTTP headers sent along with the documents, or using the
HTML document's
meta tags that are used to substitute for missing HTTP headers if the server cannot be configured to send the proper HTTP headers; see
character encodings in HTML.
Misspecification[edit]
Mojibake also occurs when the encoding is wrongly specified. This often happens between encodings that are similar. For example, the
Eudora email client for
Windows was known to send emails labelled as
ISO-8859-1 that were in reality
Windows-1252.
[3] The Mac OS version of Eudora did not exhibit this behaviour. Windows-1252 contains extra printable characters in the
C1 range (the most frequently seen being the typographically correct
quotation marks and
dashes), that were not displayed properly in software complying with the ISO standard; this especially affected software running under other operating systems such as
Unix.
Human ignorance[edit]
Of the encodings still in use, many are partially compatible with each other, with
ASCII as the predominant common subset. This sets the stage for human ignorance:
- Compatibility can be a deceptive property, as the common subset of characters are unaffected by a mixup of two encodings (see Problems in different writing systems).
- People think they are using ASCII, and tend to label whatever superset of ASCII they actually use as "ASCII". Maybe for simplification, but even in academic literature, the word "ASCII" can be found used as an example of something not compatible with Unicode, where evidently "ASCII" is Windows-1252 and "Unicode" is UTF-8.[1] Note that UTF-8 is backwards compatible with ASCII.
Overspecification[edit]
When there are layers of protocols, each trying to specify the encoding based on different information, the least certain information may be misleading to the recipient. For example, consider a
web server serving a static HTML file over HTTP. The character set may be communicated to the client in any number of 3 ways:
- in the HTTP header. This information can be based on server configuration (for instance, when serving a file off disk) or controlled by the application running on the server (for dynamic websites).
- in the file, as an HTML meta tag (
http-equiv or charset) or the encoding attribute of an XML declaration. This is the encoding that the author meant to save the particular file in.
- in the file, as a byte order mark. This is the encoding that the author's editor actually saved it in. Unless an accidental encoding conversion has happened (by opening it in one encoding and saving it in another), this will be correct. It is, however, only available in Unicode encodings such as UTF-8 or UTF-16.
Lack of Hardware/Software support[edit]
Many older hardware are typically designed to support only one character set and the character set typically cannot be altered. The character table contained within the display firmware will be localized to have characters for the country the device is to be sold in, and typically the table differs from country to country. As such, these systems will potentially display mojibake when loading text generated on a system from a different country. Likewise, many early operating systems do not support multiple encoding formats and thus will end up displaying mojibake if made to display non-standard text- early versions of
Microsoft Windows and
Palm OS for example, are localized on a per-country basis and will only support encoding standards relevant to the country the localized version will be sold in, and will display mojibake if a file containing a text in a different encoding format from the version that the OS is designed to support is opened.
Resolutions[edit]
Applications using
UTF-8 as a default encoding may achieve a greater degree of interoperability because of its widespread use and backward compatibility with
US-ASCII. UTF-8 also has the ability to be directly recognised by a simple algorithm, so that well written software should be able to avoid mixing UTF-8 up with other encodings.
The difficulty of resolving an instance of mojibake varies depending on the application within which it occurs and the causes of it. Two of the most common applications in which mojibake may occur are
web browsers and
word processors. Modern browsers and word processors often support a wide array of character encodings. Browsers often allow a user to change their
rendering engine's encoding setting on the fly, while word processors allow the user to select the appropriate encoding when opening a file. It may take some
trial and error for users to find the correct encoding.
The problem gets more complicated when it occurs in an application that normally does not support a wide range of character encoding, such as in a non-Unicode computer game. In this case, the user must change the operating system's encoding settings to match that of the game. However, changing the system-wide encoding settings can also cause Mojibake in pre-existing applications. In
Windows XP or later, a user also has the option to use
Microsoft AppLocale, an application that allows the changing of per-application locale settings. Even so, changing the operating system encoding settings is not possible on earlier operating systems such as
Windows 98; to resolve this issue on earlier operating systems, a user would have to use third party font rendering applications.
Problems in different writing systems[edit]
English[edit]
Mojibake in English texts generally occurs in punctuation, such as
em dashes (—),
en dashes (–), and
curly quotes (“,”,‘,’), but rarely in character text, since most encodings agree with
ASCII on the encoding of the
English alphabet. For example, the
pound sign "£" will appear as "£" if it was encoded by the sender as
UTF-8 but interpreted by the recipient as
CP1252 or
ISO 8859-1. If iterated, this can lead to "£", "£", "£", etc.
Some computers did in older eras have vendor-specific encodings which caused mismatch also for English text.
Commodore brand
8-bit computers used
PETSCII encoding, particularly notable for
inverting the upper and lower case compared to standard
ASCII. PETSCII printers worked fine on other computers of the era, but flipped the case of all letters. IBM mainframes use the
EBCDIC encoding which does not match ASCII at all.
Central European[edit]
Users of
Central and
Eastern European languages can also be affected. Because most computers were not connected to any network during the mid- to late-1980s, there were different character encodings for
every language with
diacritical characters.

Mojibake caused by a song title in Cyrillic (
Моя Страна) on a car audio system
Russian and other Cyrillic alphabets [edit]
Mojibake may be colloquially called
krakozyabry (кракозя́бры,
IPA:
krɐkɐˈzʲæbrɪ̈) in
Russian, which was and remains complicated by several systems for encoding
Cyrillic.
[4] The
Soviet Union and early
Russian Federationdeveloped
KOI encodings (Kod Obmena Informaciej, Код Обмена Информацией, which translates to "Code for Information Exchange"). This began with Cyrillic-only 7-bit
KOI7, based on
ASCII but with Latin and some other characters replaced with Cyrillic letters. Then came 8-bit
KOI8 encoding that is an
ASCII extension which encodes Cyrillic letters only with high-bit set octets corresponding to 7-bit codes from KOI7. It is for this reason that KOI8 text, even Russian, remains partially readable after stripping the eighth bit, which was considered as a major advantage in the age of
8BITMIME-unaware email systems. For example, words "Школа русского языка"
shkola russkogo yazyka, encoded in KOI8 and then passed through the high bit stripping process, end up rendered as "[KOLA RUSSKOGO qZYKA". Eventually KOI8 gained different flavors for Russian/Bulgarian (
KOI8-R), Ukrainian (
KOI8-U),
Belarusian (KOI8-RU) and even
Tajik (KOI8-T).
Most recently, the
Unicode encoding includes
code points for practically all the characters of all the world's languages, including all Cyrillic characters.
Before Unicode, it was necessary to match text encoding with a font using the same encoding system. Failure to do this produced unreadable
gibberish whose specific appearance varied depending on the exact combination of text encoding and font encoding. For example, attempting to view non-Unicode Cyrillic text using a font that is limited to the Latin alphabet, or using the default ("Western") encoding, typically results in text that consists almost entirely of vowels with diacritical marks. (KOI8 "Библиотека" (
biblioteka, library) becomes "âÉÂÌÉÏÔÅËÁ".) Using Win-1251 to view text in KOI8 or vice versa results in garbled text that consists mostly of capital letters (KOI8 and Win-1251 share the same ASCII region, but KOI8 has uppercase letters in the region where Win-1251 has lowercase, and vice versa.) In general, Cyrillic gibberish is symptomatic of using the wrong Cyrillic font. During the early years of the Russian sector of the World Wide Web, both KOI8 and Win-1251 were common. As of 2017, one can still encounter HTML pages in Win-1251 and, rarely, KOI8 encodings, as well as Unicode. (Estimated 1.7% of all web pages worldwide - all languages included - are encoded in Win-1251.
[5]) Though the HTML standard includes the ability to specify the encoding for any given web page in its source,
[6] this is sometimes neglected, forcing the user to switch encodings in the browser manually.
In
Bulgarian, mojibake is often called
majmunica (маймуница), meaning "monkey's [alphabet]". In
Serbian, it is called
đubre (ђубре), meaning "
trash". Unlike the former USSR, South Slavs never used something like KOI8, and Code Page 1251 was the dominant Cyrillic encoding there before Unicode. Therefore, these languages experienced fewer encoding incompatibility troubles than Russian. In the 1980s, Bulgarian computers used their own
MIK encoding, which is superficially similar to (although incompatible with) CP866.
- Example
| Russian example: | Кракозябры (krakozyabry, garbage characters) |
|---|
| File encoding | Setting in browser | Result |
|---|
| MS-DOS 855 | ISO 8859-1 | Æá ÆÖóÞ¢áñ |
| KOI8-R | ISO 8859-1 | ëÒÁËÏÚÑÂÒÙ |
| UTF-8 | KOI8-R | п я─п╟п╨п╬п╥я▐п╠я─я▀ |
Prior to the creation of
ISO 8859-2 in 1987, users of various computing platforms used their own
character encodings such as
AmigaPL on Amiga, Atari Club on Atari ST and Masovia, IBM
CP852,
Mazovia and
Windows CP1250 on IBM PCs. Polish companies selling early
DOS computers created their own mutually-incompatible ways to encode Polish characters and simply reprogrammed the
EPROMs of the video cards (typically
CGA,
EGA, or
Hercules) to provide
hardware code pages with the needed glyphs for Polish—arbitrarily located without reference to where other computer sellers had placed them.
The situation began to improve when, after pressure from academic and user groups,
ISO 8859-2 succeeded as the "Internet standard" with limited support of the dominant vendors' software (today largely replaced by Unicode). With the numerous problems caused by the variety of encodings, even today some users tend to refer to Polish diacritical characters as
krzaczki ([kshach-kih], lit. "little shrubs").
Yugoslav languages[edit]
Slovenian,
Croatian,
Bosnian,
Serbian, the variants of the Yugoslav
Serbo-Croatian language, add to the basic Latin alphabet the letters š, đ, č, ć, ž, and their capital counterparts Š, Đ, Č, Ć, Ž (only č/Č, š/Š and ž/Ž in Slovenian; officially, although others are used when needed, mostly in foreign names, as well). All of these letters are defined in
Latin-2 and
Windows-1250, while only some (š, Š, ž, Ž, Đ) exist in the usual OS-default
Windows-1252, and are there because of some other languages.
Although Mojibake can occur with any of these characters, the letters that are not included in Windows-1252 are much more prone to errors. Thus, even nowadays, "šđčćž ŠĐČĆŽ" is often displayed as "šðèæž ŠÐÈÆŽ", although ð, è, æ, È, Æ are never used in Slavic languages.
When confined to basic ASCII (most user names, for example), common replacements are: š→s, đ→dj, č→c, ć→cj, ž→z (capital forms analogously, with Đ→Dj or Đ→DJ depending on word case). All of these replacements introduce ambiguities, so reconstructing the original from such a form is usually done manually if required.
The
Windows-1252 encoding is important because the English versions of the Windows operating system are most widespread, not localized ones.
[citation needed] The reasons for this include a relatively small and fragmented market, increasing the price of high quality localization, a high degree of software piracy (in turn caused by high price of software compared to income), which discourages localization efforts, and people preferring English versions of Windows and other software .
[citation needed]
The drive to
differentiate Croatian from Serbian, Bosnian from Croatian and Serbian, and now even
Montenegrin from the other three creates many problems. There are many different localizations, using different standards and of different quality. There are no common translations for the vast amount of computer terminology originating in English. In the end, people use adopted English words ("kompjuter" for "computer", "kompajlirati" for "compile," etc.), and if they are unaccustomed to the translated terms may not understand what some option in a menu is supposed to do based on the translated phrase. Therefore, the people who understand English, as well as those who are accustomed to English terminology (which are most, because English terminology is also mostly taught in schools because of these problems) regularly choose the original English versions of non-specialist software.
Newer versions of English Windows allow the ANSI codepage to be changed (older versions require special English versions with this support), but this setting can be and often was incorrectly set. For example, Windows 98/Me can be set to most non-right-to-left
single-byte codepages including 1250, but only at install time.
Hungarian[edit]
Hungarian is another affected language, which uses the 26 basic English characters, plus the accented forms á, é, í, ó, ú, ö, ü (all present in the Latin-1 character set), plus the 2 characters
ő and
ű, which are not in Latin-1. These 2 characters can be correctly encoded in Latin-2, Windows-1250 and Unicode. Before Unicode became common in e-mail clients, e-mails containing Hungarian text often had the letters ő and ű corrupted, sometimes to the point of unrecognizability. It is common to respond to an e-mail rendered unreadable (see examples below) by character mangling (referred to as "betűszemét", meaning "garbage lettering") with the phrase "Árvíztűrő tükörfúrógép", a nonsense phrase (literally "Flood-resistant mirror-drilling machine") containing all accented characters used in Hungarian.
Examples[edit]
| Source encoding | Target encoding | Result | Occurrence |
|---|
| Hungarian example | ÁRVÍZTŰRŐ TÜKÖRFÚRÓGÉP
árvíztűrő tükörfúrógép |
|---|
| CP 852 | CP 437 | ╡RV╓ZTδRè TÜKÖRFΘRαGÉP
árvízt√rï tükörfúrógép | This was very common in DOS-era when the text was encoded by the Central European CP 852 encoding; however, the operating system, a software or printer used the default CP 437 encoding. Please note that small-case letters are mainly correct, exception with ő (ï) and ű (√). Ü/ü is correct because CP 852 was made compatible with German. Nowadays occurs mainly on printed prescriptions and cheques. |
|---|
| CWI-2 | CP 437 | ÅRVìZTÿRº TÜKÖRFùRòGÉP
árvíztûrô tükörfúrógép | The CWI-2 encoding was designed so that the text remains fairly well-readable even if the display or printer uses the default CP 437 encoding. This encoding was heavily used in the 1980s and early 1990s, but nowadays it is completely deprecated. |
|---|
| Windows-1250 | Windows-1252 | ÁRVÍZTÛRÕ TÜKÖRFÚRÓGÉP
árvíztûrõ tükörfúrógép | The default Western Windows encoding is used instead of the Central-European one. Only ő-Ő (õ-Õ) and ű-Ű (û-Û) are wrong, but the text is completely readable. This is the most common error nowadays; due to ignorance, it occurs often on webpages or even in printed media. |
|---|
| CP 852 | Windows-1250 | µRVÖZTëRŠ TšK™RFéRŕGP
rvˇztűr‹ tk"rfŁr˘g‚p | Central European Windows encoding is used instead of DOS encoding. The use of ű is correct. |
|---|
| Windows-1250 | CP 852 | ┴RV═ZT█RŇ T▄KÍRF┌RËG╔P
ßrvÝztűr§ tŘk÷rf˙rˇgÚp | Central European DOS encoding is used instead of Windows encoding. The use of ű is correct. |
|---|
| Quoted-printable | 7-bitASCII | =C1RV=CDZT=DBR=D5 T=DCK=D6RF=DAR=D3G=C9P
=E1rv=EDzt=FBr=F5 t=FCk=F6rf=FAr=F3g=E9p | Mainly caused by wrongly configured mail servers but may occur in SMS messages on some cell-phones as well. |
|---|
| UTF-8 | Windows-1252 | ÃRVÃZTÅ°RÅ TÃœKÖRFÚRÃ"GÉP
árvÃztűrÅ‘ tükörfúrógép | Mainly caused by wrongly configured web services or webmail clients, which were not tested for international usage (as the problem remains concealed for English texts). In this case the actual (often generated) content is in UTF-8; however, it is not configured in the HTML headers, so the rendering engine displays it with the default Western encoding. |
|---|
Other Western European languages[edit]
- å, ä and ö in Finnish and Swedish
- à, ç, è, é, ï, í, ò, ó, ú, ü in Catalan
- å, æ and ø in Norwegian and Danish
- á, é, ó, ý, è, ë, ï in Dutch
- ä, ö, ü and ß in German
- á, ð, í, ó, ú, ý, æ and ø in Faroese
- á, ð, é, í, ó, ú, ý, þ, æ and ö in Icelandic
- à, â, ç, è, é, ë, ê, ï, î, ö, ô, ù, û, ÿ, æ, œ in French
- à, è, é, ì, ò, ù in Italian
- á, é, í, ñ, ó, ú, ï, ü, ¡, ¿ in Spanish
- à, á, â, ã, ç, é, ê, í, ó, ô, õ, ú in Portuguese (ü no longer used)
- á, é, í, ó, ú in Irish
- £ in British English
... and their uppercase counterparts, if applicable.
These are languages for which the
iso-8859-1 character set (also known as
Latin 1 or
Western) has been in use. However, iso-8859-1 has been obsoleted by two competing standards, the backward compatible
windows-1252, and the slightly altered
iso-8859-15. Both add the
Euro sign € and the French œ, but otherwise any confusion of these three character sets does not create mojibake in these languages. Furthermore, it is always safe to interpret iso-8859-1 as windows-1252, and fairly safe to interpret it as iso-8859-15, in particular with respect to the Euro sign, which replaces the rarely used
currency sign (¤). However, with the advent of
UTF-8, mojibake has become more common in certain scenarios, e.g. exchange of text files between
UNIX and
Windows computers, due to UTF-8's incompatibility with Latin-1 and Windows-1252. But UTF-8 has the ability to be directly recognised by a simple algorithm, so that well written software should be able to avoid mixing UTF-8 up with other encodings, so this was most common when many had software not supporting UTF-8. Most of these languages were supported by MS-DOS default CP437 and other machine default encodings, except ASCII, so problems when buying a operating system version were less common. Windows and MS-DOS are not compatible however.
In Swedish, Norwegian, Danish and German, vowels are rarely repeated, and it is usually obvious when one character gets corrupted, e.g. the second letter in "kärlek" (kärlek, "love"). This way, even though the reader has to guess between å, ä and ö, almost all texts remain legible. Finnish text, on the other hand, does feature repeating vowels in words like hääyö ("wedding night") which can sometimes render text very hard to read (e.g. hääyö appears as "hääyö"). Icelandic and Faroese have ten and eight possibly confounding characters, respectively, which thus can make it more difficult to guess corrupted characters; Icelandic words like þjóðlöð ("outstanding hospitality") become almost entirely unintelligible when rendered as "þjóðlöð".
In German, Buchstabensalat ("letter salad") is a common term for this phenomenon, and in Spanish, deformación (literally deformation).
Some users transliterate their writing when using a computer, either by omitting the problematic diacritics, or by using digraph replacements (å → aa, ä/æ → ae, ö/ø → oe, ü → ue etc.). Thus, an author might write "ueber" instead of "über", which is standard practice in German when
umlauts are not available. The latter practice seems to be better tolerated in the German language sphere than in the
Nordic countries. For example, in Norwegian, digraphs are associated with archaic Danish, and may be used jokingly. However, digraphs are useful in communication with other parts of the world. As an example, the Norwegian football player
Ole Gunnar Solskjær had his name spelled "SOLSKJAER" on his back when he played for
Manchester United.
An artifact of
UTF-8 misinterpreted as
ISO-8859-1, "Ring meg nå" ("
Ring meg nå"), was seen in an SMS scam raging in Norway in June 2014.
[7]
- Examples
Caucasian languages[edit]
The writing systems of certain
languages of the Caucasus region, including the scripts of
Georgian and
Armenian, may produce mojibake. This problem is particularly acute in the case of
ArmSCII or ARMSCII, a set of obsolete character encodings for the Armenian alphabet which have been superseded by Unicode standards. ArmSCII is not widely used because of a lack of support in the computer industry. For example,
Microsoft Windows does not support it.
Asian encodings[edit]
Another type of mojibake occurs when text is erroneously parsed in a multi-byte encoding, such as one of the encodings for
East Asian languages. With this kind of mojibake more than one (typically two) characters are corrupted at once, e.g. "k舐lek" (
kärlek) in Swedish, where "är" is parsed as "舐". Compared to the above mojibake, this is harder to read, since letters unrelated to the problematic å, ä or ö are missing, and is especially problematic for short words starting with å, ä or ö such as "än" (which becomes "舅"). Since two letters are combined, the mojibake also seems more random (over 50 variants compared to the normal three, not counting the rarer capitals). In some rare cases, an entire text string which happens to include a pattern of particular word lengths, such as the sentence "
Bush hid the facts", may be misinterpreted.
Japanese[edit]
In
Japanese, the phenomenon is, as mentioned, called
mojibake (文字化け). It is a particular problem in Japan due to the numerous different encodings that exist for Japanese text. Alongside Unicode encodings like UTF-8 and UTF-16, there are other standard encodings, such as
Shift-JIS (Windows machines) and
EUC-JP (UNIX systems). Mojibake, as well as being encountered by Japanese users, is also often encountered by non-Japanese when attempting to run software written for the Japanese market.
Chinese[edit]
In
Chinese, the same phenomenon is called
Luàn mǎ (
Pinyin,
Simplified Chinese 乱码,
Traditional Chinese 亂碼, meaning chaotic code), and can occur when computerised text is encoded in one
Chinese character encoding but is displayed using the wrong encoding. When this occurs, it is often possible to fix the issue by switching the character encoding without loss of data. The situation is complicated because of the existence of several Chinese character encoding systems in use, the most common ones being:
Unicode,
Big5, and
Guobiao (with several backward compatible versions), and the possibility of Chinese characters being encoded using Japanese encoding.
It is easy to identify the original encoding when luanma occurs in Guobiao encodings:
| Original encoding | Viewed as | Result | Original text | Note |
|---|
| Big5 | GB | 瓣в眏 | 三國志11威力加強版 | Lots of blank or undisplayable characters with occasional Chinese characters |
| Shift-JIS | GB | 暥帤壔偗僥僗僩 | 文字化けテスト | Kana is displayed as characters with the radical 亻, while kanji are other characters. Most of them are extremely uncommon and not in practical use in modern Chinese. |
| EUC-KR | GB | 叼力捞钙胶 抛农聪墨 | 디제이맥스 테크니카 | Random common Simplified Chinese characters which in most cases make no sense. Easily identifiable because of spaces between every several characters. |
An additional problem is caused when encodings are missing characters, which is common with rare or antiquated characters that are still used in personal or place names. Examples of this are
Taiwanese politicians
Wang Chien-shien (Chinese:
王建煊; pinyin:
Wáng Jiànxuān)'s "煊",
Yu Shyi-kun (simplified Chinese:
游锡堃; traditional Chinese:
游錫堃; pinyin:
Yóu Xíkūn)'s "堃" and singer
David Tao (Chinese:
陶喆; pinyin:
Táo Zhé)'s "喆" missing in
Big5, ex-PRC Premier
Zhu Rongji (Chinese:
朱镕基; pinyin:
Zhū Róngjī)'s "镕" missing in
GB2312,
copyright symbol "©" missing in
GBK.
[8]
Newspapers have dealt with this problem in various ways, including using software to combine two existing, similar characters; using a picture of the personality; or simply substituting a homophone for the rare character in the hope that the reader would be able to make the correct inference.
Indic text[edit]
A similar effect can occur in
Brahmic or Indic scripts of
South Asia, used in such
Indo-Aryan or Indic languages as
Hindustani (Hindi-Urdu),
Bengali,
Punjabi,
Marathi, and others, even if the character set employed is properly recognized by the application. This is because, in many Indic scripts, the rules by which individual letter symbols combine to create symbols for syllables may not be properly understood by a computer missing the appropriate software, even if the glyphs for the individual letter forms are available.
A particularly notable example of this is the old
Wikipedia logo, which attempts to show the character analogous to "wi" (the first syllable of "Wikipedia") on each of many puzzle pieces. The puzzle piece meant to bear the
Devanagari character for "wi" instead used to display the "wa" character followed by an unpaired "i"
modifier vowel, easily recognizable as mojibake generated by a computer not configured to display Indic text.
[9] The logo as redesigned as of May 2010
has fixed these errors.
The idea of Plain Text requires the operating system to provide a font to display Unicode codes. This font is different from OS to OS for Singhala and it makes orthographically incorrect glyphs for some letters (syllables) across all operating systems. For instance, the 'reph', the short form for 'r' is a diacritic that normally goes on top of a plain letter. However, it is wrong to go on top of some letters like 'ya' or 'la' but it happens in all operating systems. This appears to be a fault of internal programming of the fonts. In Macintosh / iPhone, the muurdhaja l (dark l) and 'u' combination and its long form both yield wrong shapes.
Some Indic and Indic-derived scripts, most notably
Lao, were not officially supported by
Windows XP until the release of
Vista.
[10] However, various sites have made free-to-download fonts.
African languages[edit]
In certain
writing systems of Africa, unencoded text is unreadable. Texts that may produce mojibake include those from the
Horn of Africa such as the
Ge'ez script in
Ethiopia and
Eritrea, used for
Amharic,
Tigre, and other languages, and the
Somali language, which employs the
Osmanya alphabet. In
Southern Africa, the
Mwangwego alphabet is used to write languages of
Malawi and the
Mandombe alphabet was created for the
Democratic Republic of the Congo, but these are not generally supported. Various other writing systems native to
West Africa present similar problems, such as the
N'Ko alphabet, used for
Manding languages in
Guinea, and the
Vai syllabary, used in
Liberia.
Another affected language is
Arabic (see
below). The text becomes unreadable when the encodings do not match.
Examples[edit]
| File encoding | Setting in browser | Result |
|---|
| Arabic example: |  (Universal Declaration of Human Rights) (Universal Declaration of Human Rights) |
|---|
| Browser rendering: | الإعلان العالمى لحقوق الإنسان |
|---|
| UTF-8 | Windows-1252 | اÙ"إعÙ"ان اÙ"عاÙ"مى Ù"Øقوق اÙ"إنسان |
|---|
| KOI8-R | О╩©ь╖ы└ь╔ь╧ы└ь╖ы├ ь╖ы└ь╧ь╖ы└ы┘ы┴ ы└ь╜ы┌ы┬ы┌ ь╖ы└ь╔ы├ьЁь╖ы├ |
|---|
| ISO 8859-5 | яЛПиЇй�иЅиЙй�иЇй� иЇй�иЙиЇй�й�й� й�ий�й�й� иЇй�иЅй�иГиЇй� |
|---|
| CP 866 | я╗┐╪з┘Д╪е╪╣┘Д╪з┘Ж ╪з┘Д╪╣╪з┘Д┘Е┘Й ┘Д╪н┘В┘И┘В ╪з┘Д╪е┘Ж╪│╪з┘Ж |
|---|
| ISO 8859-6 | ُ؛؟ظ�ع�ظ�ظ�ع�ظ�ع� ظ�ع�ظ�ظ�ع�ع�ع� ع�ظع�ع�ع� ظ�ع�ظ�ع�ظ�ظ�ع� |
|---|
| ISO 8859-2 | اŮ�ŘĽŘšŮ�اŮ� اŮ�ؚاŮ�Ů�Ů� Ů�ŘŮ�Ů�Ů� اŮ�ŘĽŮ�ساŮ� |
|---|
| Windows-1256 | Windows-1252 | ÇáÅÚáÇä ÇáÚÇáãì áÍÞæÞ ÇáÅäÓÇä |
|---|
The examples in this article do not have UTF-8 as browser setting, because UTF-8 is easily recognisable, so if a browser supports UTF-8 it should recognise it automatically, and not try to interpret something else as UTF-8.